Цели и задачи регрессионного тестирования
При корректировках программы необходимо гарантировать сохранение качества. Для этого используется регрессионное тестирование - дорогостоящая, но необходимая деятельность в рамках этапа сопровождения, направленная на перепроверку корректности измененной программы. В соответствии со стандартным определением, регрессионное тестирование - это выборочное тестирование, позволяющее убедиться, что изменения не вызвали нежелательных побочных эффектов, или что измененная система по-прежнему соответствует требованиям.
Главной задачей этапа сопровождения является реализация систематического процесса обработки изменений в коде. После каждой модификации программы необходимо удостовериться, что на функциональность программы не оказал влияния модифицированный код. Если такое влияние обнаружено, говорят о регрессионном дефекте. Для регрессионного тестирования функциональных возможностей, изменение которых не планировалось, используются ранее разработанные тесты. Одна из целей регрессионного тестирования состоит в том, чтобы, в соответствии с используемым критерием покрытия кода (например, критерием покрытия потока операторов или потока данных), гарантировать тот же уровень покрытия, что и при полном повторном тестировании программы. Для этого необходимо запускать тесты, относящиеся к измененным областям кода или функциональным возможностям.
Пусть T = {t1, t2, ..., tN} - множество из N тестов, используемое при первичной разработке программы P, а T'


Другая цель регрессионного тестирования состоит в том, чтобы удостовериться, что программа функционирует в соответствии со своей спецификацией, и что изменения не привели к внесению новых ошибок в ранее протестированный код.
Эта цель всегда может быть достигнута повторным выполнением всех тестов регрессионного набора, но более перспективно отсеивать тесты, на которых выходные данные модифицированной и старой программы не могут различаться. Результаты сравнения выборочных методов и метода повторного прогона всех тестов приведены в таблица 11.1.
| Прост в реализации | Требует дополнительных расходов при внедрении |
| Дорогостоящий и неэффективный | Способно уменьшать расходы за счет исключения лишних тестов |
| Обнаруживает все ошибки, которые были бы найдены при исходном тестировании | Может приводить к пропуску ошибок |


Реалистичный вариант решения задачи выборочного регрессионного тестирования состоит в получении полезной информации по результатам выполнения P и объединения этой информации с данными статического анализа для получения множества T'реальное в виде аппроксимации T'идеальное. Этот подход применяется во всех известных выборочных методах регрессионного тестирования, основанных на анализе кода.
Множество T' реальное должно включать все тесты из T, активирующие измененный код, и не включать никаких других тестов, то есть тест t
Если некоторый тест t задействует в P тот же код, что и в P', выходные данные P и P' для t различаться не будут. Из этого следует, что если P(t)
Важной задачей регрессионного тестирования является также уменьшение стоимости и сокращение времени выполнения тестов.
Рассмотрим отбор тестов на примере рис. 11.1. Код, покрываемый тестами, выделен цветом и штриховкой. Легко заметить, что код, покрываемый тестом 1, не изменился с предыдущей версии, следовательно, повторное выполнение теста 1 не требуется. Напротив, код, покрываемый тестами 2, 3 и 4, изменился; следовательно, требуется их повторный запуск.
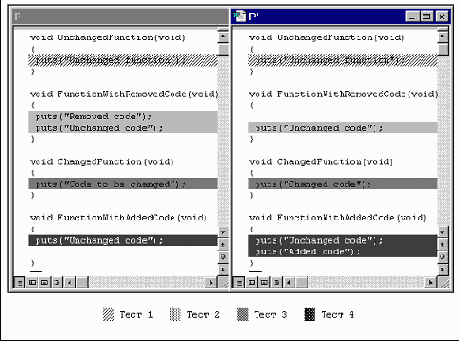
Рис. 11.1. Отбор тестов для множества T'.